http://www.meetup.com/vancouver-ruby-rails/events/21277581/
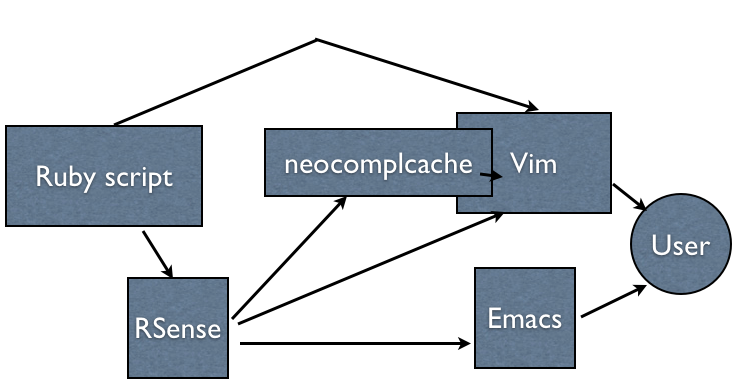
structure
RSense
A Ruby development toolset
- Code completion
- Type inspection
- Definition jump
RSense code completion
a.rb
a = '123'
b = a.to_i
b.
rsense command
$ rsense code-completion --file=a.rb --location=3:2
completion: to_enum Object#to_enum Object METHOD
completion: succ! String#succ! String METHOD
completion: swapcase! String#swapcase! String METHOD
completion: instance_variable_defined? Object#instance_variable_defined? Object METHOD
...
Implementation
- Front-end command bin/rsense
- Back-end server process with Java&JRuby
- Type-inference algorithm "modified-Cartesian Product Algorithm"
limitations
- classes in the buffer
- 1.8 built-in libraries
- incorrect syntax
- evals and exceptions
Vim

Vim
Vim and me
- fullscreen MacVim
- vimshell (no other terminals)
- neocomplcache
- unite
- quickrun
RSense built-in Vim plugin
User-defined completion <C-x><C-u>
a = '123'
b = a.to_i
b._
Insert-mode completions in general
<C-n>Keyword<C-x><C-f>File name<C-x><C-s>English spelling<C-x><C-o>Omni<C-x><C-u>User-defined
neocomplcache
Insert-mode auto-completion plugin framework
- No key mapping necessary
- Integrates lots of completions
RSense as omni func
~/.vimrc
let g:rsenseUseOmniFunc = 1
let g:rsenseHome = expand('~/git/rsense')
let g:neocomplcache_omni_patterns = {}
let g:neocomplcache_omni_patterns.ruby = '[^. *\t]\.\w*\|\h\w*::'
one more thing
neco-: prefix for neocomplcache plugins- neco-rake: rake task completion
structure
http://ujihisa.blogspot.comhttp://twitter.com/ujm- google
rsense - google
neocomplcacheif you are a Vimmer
